Rise of the Software Factory
I gave this talk at AI Engineer World Fair in San Francisco, June 2026.
This is the full day-one livestream; my talk starts at roughly 2:10:00 (jump straight to it).
This is a loose write-up of my talk, not an exact transcript. Tell me what you think, and if you disagree, even better.
Everyone is suddenly talking about software factories, but very few have actually built one and fewer still are willing to show the process. So I want to start with the obvious questions of why this is happening now and what a software factory actually means.

No one knows what software factory means
Everyone is launching software factories. Enterprises share their transformations, LinkedIn is full of thought leadership, and this conference even has a dedicated track for them. What is much harder to find is honest evidence that any of it works in production, or a clear answer about the conditions it needs and how autonomous software really is today. Those are the questions people actually ask when the marketing fades: what a software factory is, whether they should build their own and how, what genuinely works in production, and at what cost.
I define a software factory as the whole cycle of developing software that runs autonomously, which means far more than writing code: it covers the spec, the build, the validation, the deploy, and the learning that comes back afterward. The better mental image is not a chatbot that codes but a factory floor, with parallel lines each handling a different task at a different level of autonomy, where you set policy and priorities at the top and the floor reports back up to you.

That is why the rest of the talk is about three properties that make this floor trustworthy: agnostic, autonomous, and always-improving.
The software factory was not possible two years ago
Karpathy's "Software 2.0" essay in 2017 was the intellectual precursor, and then each layer arrived in turn: Copilot in 2021 for autocomplete, ChatGPT in 2022 for conversation, GPT-4 and bigger context windows in 2023 for real code generation, better reasoning in 2024 for multi-step tasks, and persistent environments with long-running missions in 2025 for genuine autonomy. Every one of those layers had to exist before the factory could.
The length of task an agent can handle doubles roughly every seven months, and for years the AI was a brain with no body, able to plan, retry, and narrate but never actually execute across a full cycle.
The idea itself is not new, since AutoGPT and BabyAGI were already looping and iterating on software back in 2023, they just did not work yet. The models hallucinated, context windows were too small, reasoning was too weak, and there were no good isolated environments where an agent could actually run, so every one of those problems had to be fixed before the factory became real.

The way I like to define it is by what it goes beyond. A software factory is much more than a coding agent, or even a swarm of thousands of coding agents, because generating code is the easy part. Engineers spend most of their time not on writing code but on everything that surrounds it, and that surrounding work is exactly what a factory has to handle. The right mental model is building a real team of people, because with that many agents testing, validating, and iterating, the whole thing turns into chaos unless you design it deliberately.
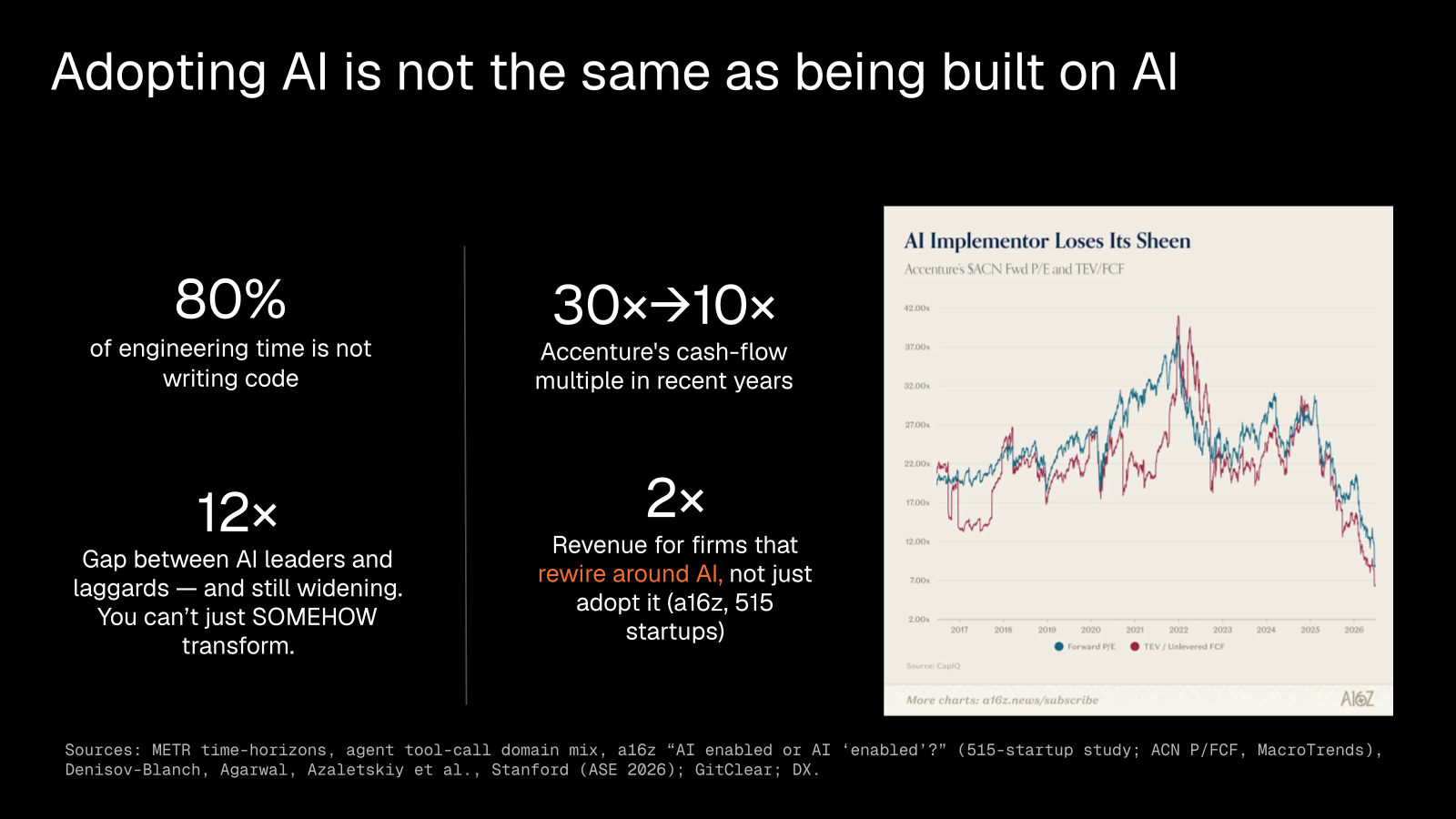
The firms that rewire their organization around AI, rather than bolting it onto their existing process, pull steadily ahead of the ones that only adopt it, and the gap between leaders and laggards keeps widening because readiness is what compounds over time. A software factory is something you build and own, not a consultancy you hire.
Accenture's valuation multiple peaked near 30x in early 2025 and has come down to about 10x. The market is pricing the difference between advising on AI and actually shipping it.
Electrification is the useful analogy here. When factories first got electricity, they bolted a motor onto the old steam-era layout and saw almost no gains, and the real jump only came once they redesigned the whole factory around electricity. AI works the same way, so bolting agents onto today's process just leaves you with the old factory and a new motor, while redesigning the process around them is what actually produces a software factory.
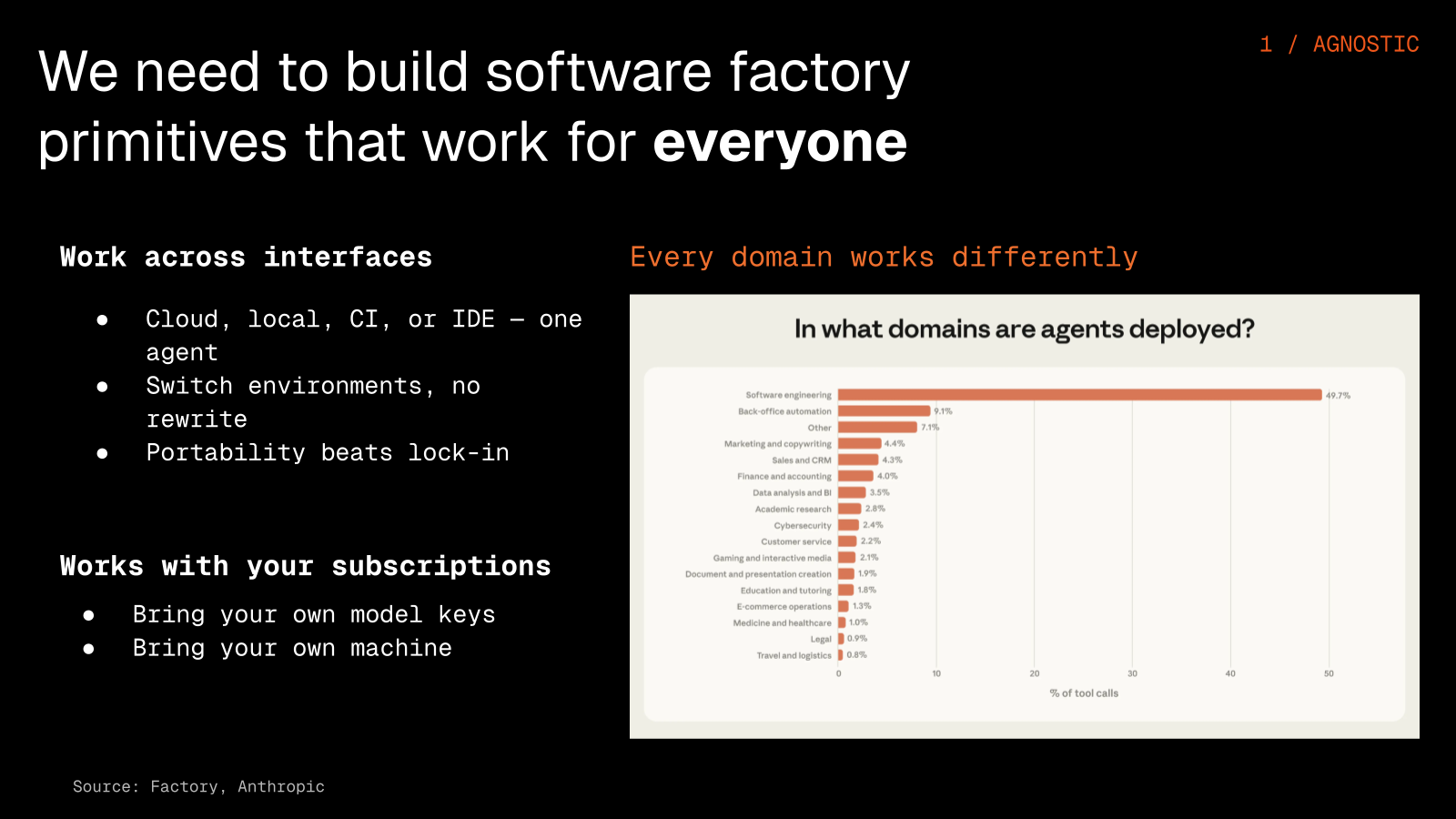
That factory should stay independent instead of locking you into one platform, work with the models and tools you already use, be trusted enough to run genuinely autonomously, and carry context so that it learns with use.

Do not lock yourself into one environment or subscription, because the same agent should be able to run in the cloud, locally, in CI, and in your IDE, and once it can, that portability becomes real leverage and keeps you clear of vendor lock-in.
Resources for this section:
- Karpathy, "Software 2.0" (2017)
- METR: Measuring AI Ability to Complete Long Tasks
- MacroTrends: Accenture P/FCF historical data
1. Agnostic
Brian Armstrong, the CEO of Coinbase, shared how his team cut their AI spend significantly while still token-maxing, and they did it through better default models, routing, and caching rather than through friction and spend alerts, so their token usage grew exponentially while the actual spend stayed flat.
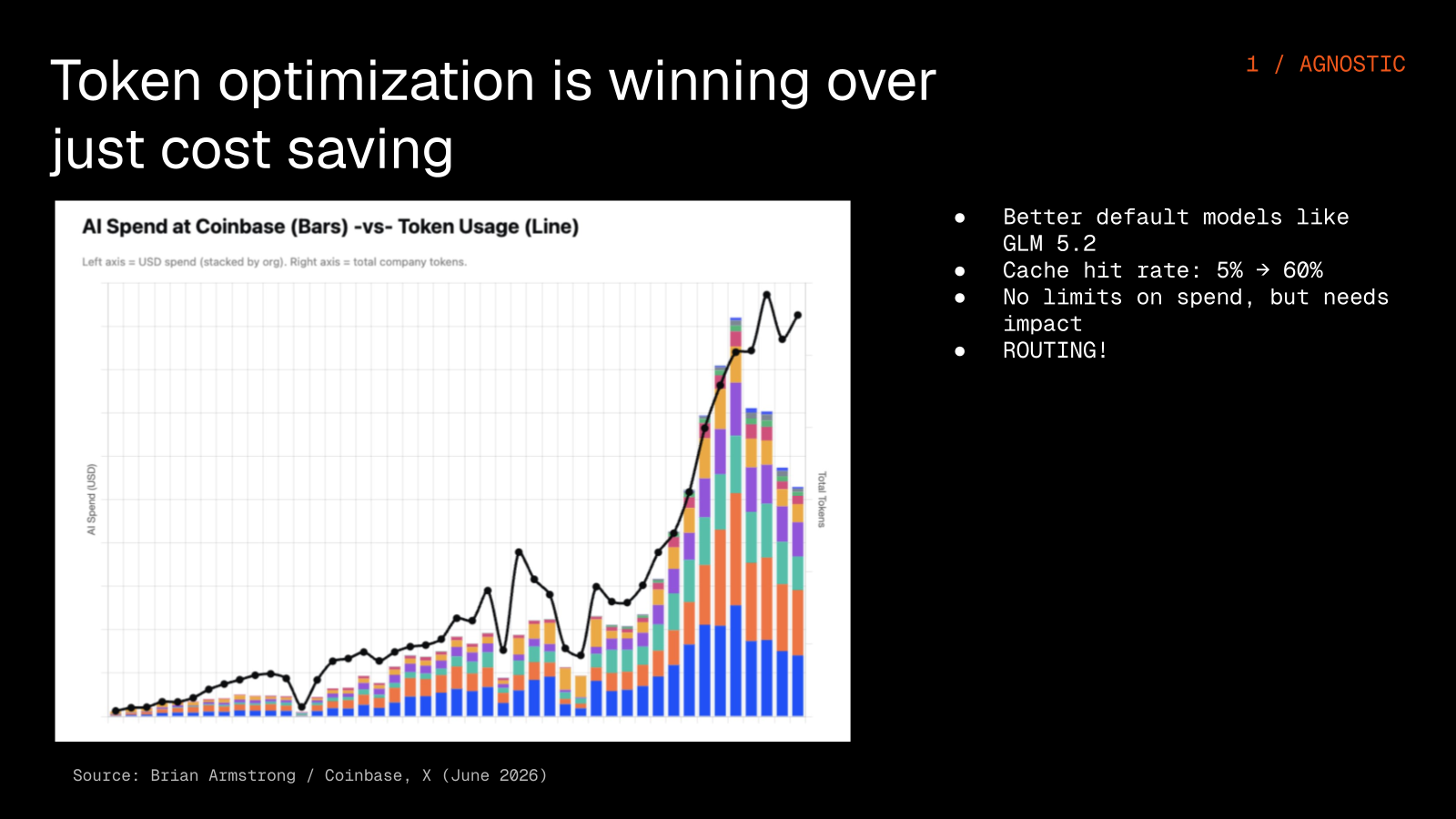
When everything gets commoditized, the smarter move is to use all of it rather than bet on a single model. Routing does more than cut cost, because it also buys you reliability through failover between providers and speed by sending the simple tasks to the fastest model, all without sacrificing quality.
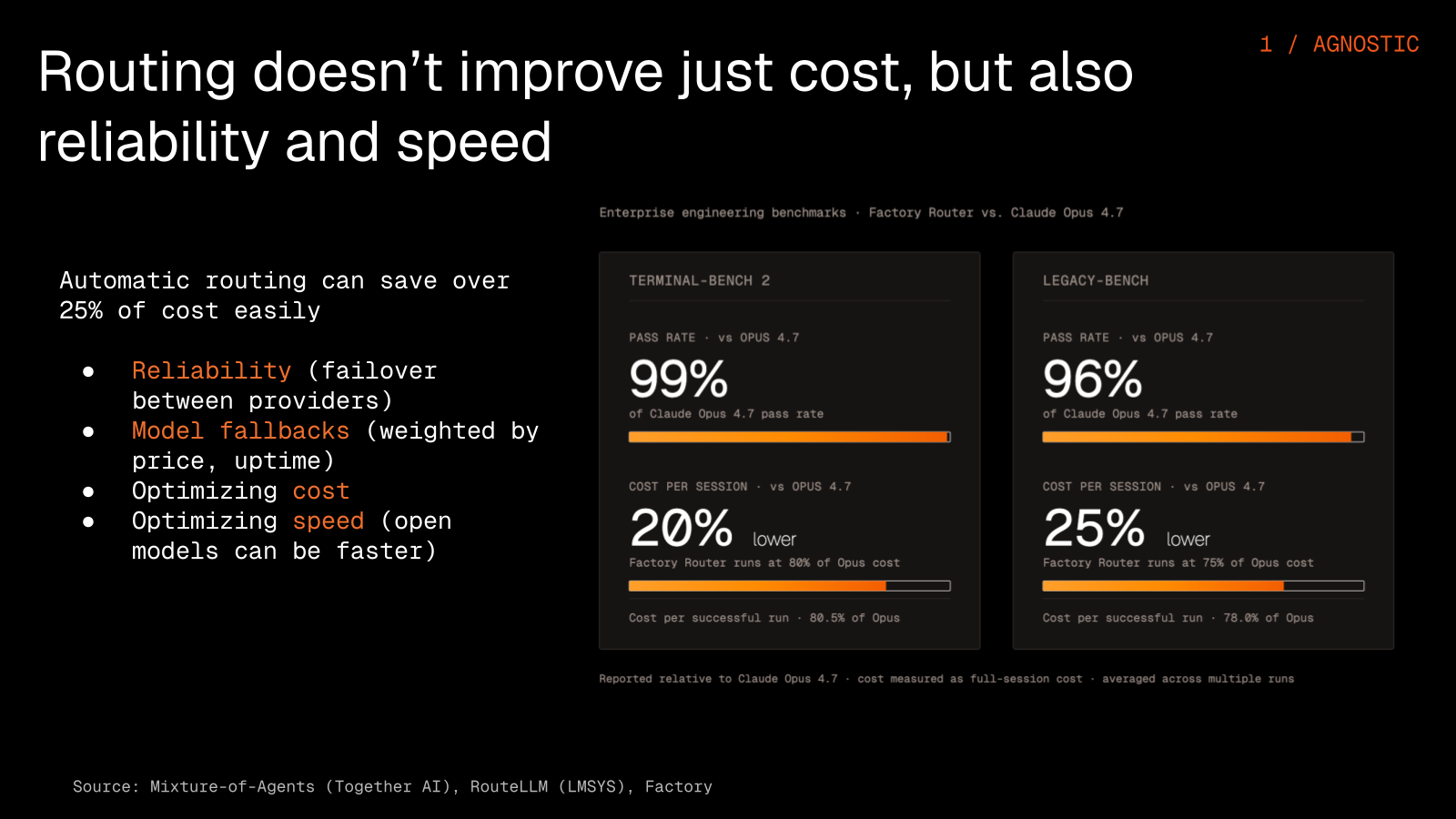
This is the Factory Router. When an engineer describes a task in plain language, the classifier reads it and scores the message content, the recent tool calls, the repo size, the language mix, and the difficulty, then assigns each model a quality-probability score and automatically picks the best fit for the job.
There are really four parts to it. You start by assigning a task, and because an organization can set different default models and permissions per role, sales, marketing, and engineers each begin from a sensible default. The classifier then scores how hard the task is, you set a quality threshold for what counts as good enough, and the router picks the cheapest model it predicts will clear that threshold. Our benchmark is deliberately conservative and still shows around 25% savings, which is likely higher in practice.
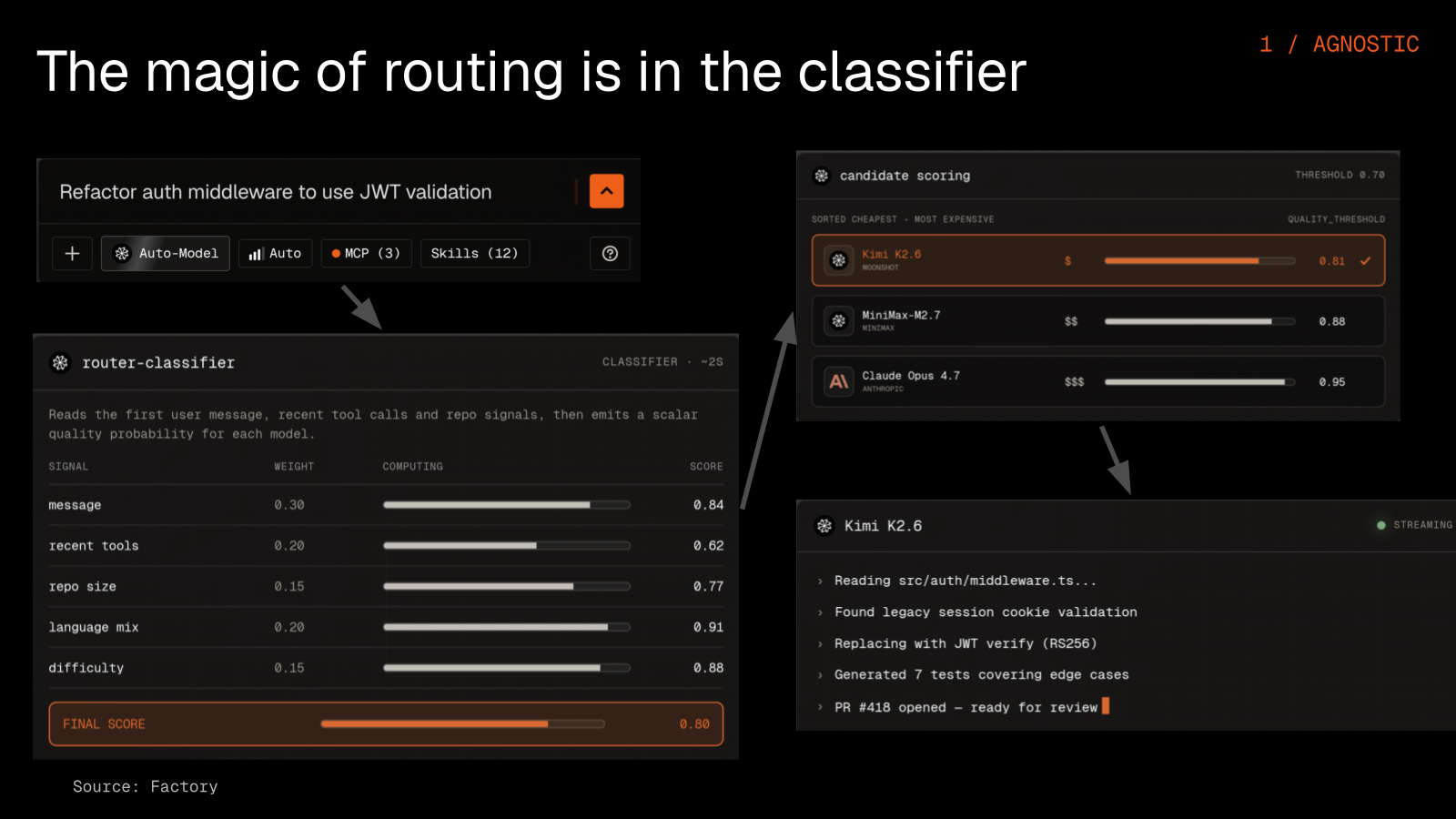
A fair question is what happens when the routing gets it wrong. The router does not lock in its first decision, so it can upgrade mid-conversation and switch to a stronger model when a task turns out harder than expected, and the user always keeps an override.
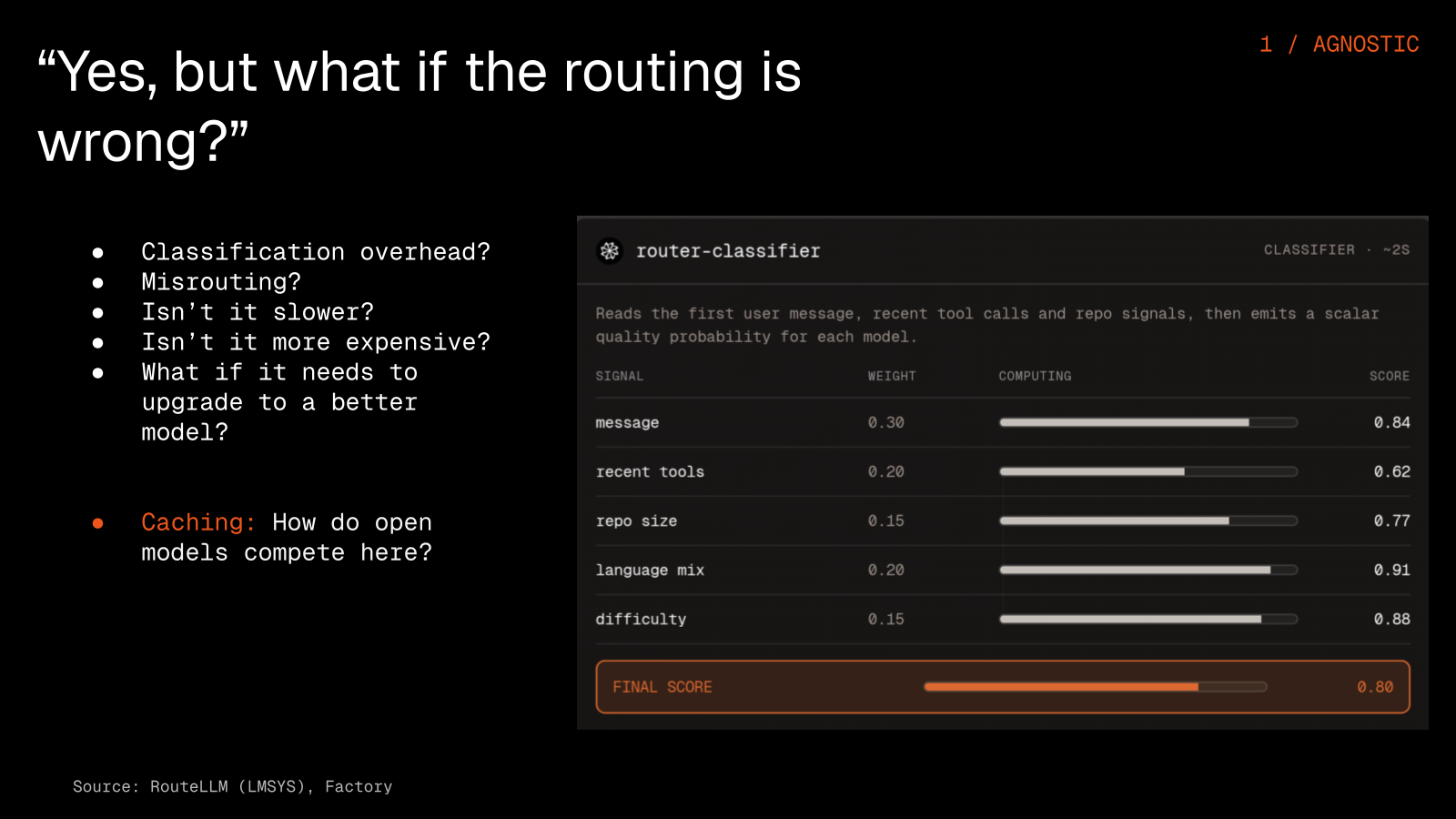
Caching matters so much for agents because a transformer does not really remember your conversation; on every turn it re-reads the entire history from scratch. Prefix caching lets it skip recomputing the parts that did not change, like the system prompt, the tools, and the skills, which makes the second turn roughly ten times cheaper than the first, and we pass those savings straight through to end users.
Caching is not a moat, though, since anyone can do it, including open models hosted on your own dedicated compute. The final price a user sees is a pricing decision rather than a technical one, and it comes down to how much of the savings you choose to pass on and what deals you strike with providers.

Resources for this section:
- Brian Armstrong / Coinbase on X
- Factory Router
- Anthropic: prompt caching
- Factory: introducing the Factory Router
2. Autonomous
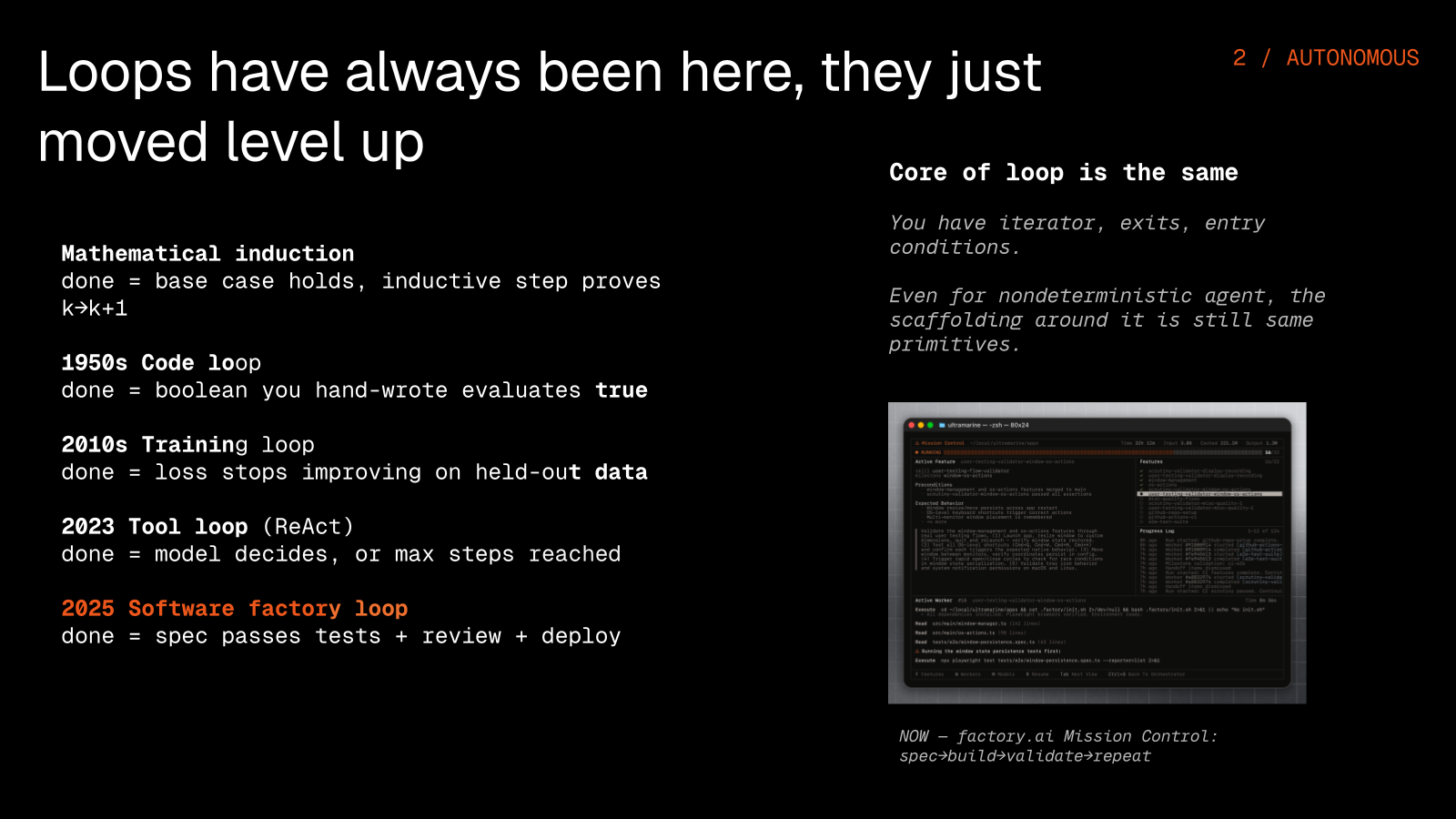
The loop never went away, it just moved up a layer. On the left is the loop we all started with, a while-loop in code, and on the right is the same shape expressed in an agent that iterates, checks its exit conditions, and continues. You can trace the same pattern through mathematical induction, code loops, training loops, ReAct tool loops, and now software factory loops, because the core never changes: an iterator, some exits, and a set of entry conditions.
Here is a real example. Someone asked Droid for a 750mm Factory rotor logo, wall-mounted, printed on their Bambu X1C, and after that one prompt and a single clarifying question Droid pulled the SVG from our brand assets, converted it into a 3D model, sliced it for the printer, and output the G-code, all the way through with no hand-holding.

I believe agents will eventually run for a year without interruption. Task length doubles roughly every seven months, but only at 50% reliability, so the real frontier now is reliability over long horizons rather than raw capability. Capability is largely solved at this point, and reliability is where the real advantage now lives.
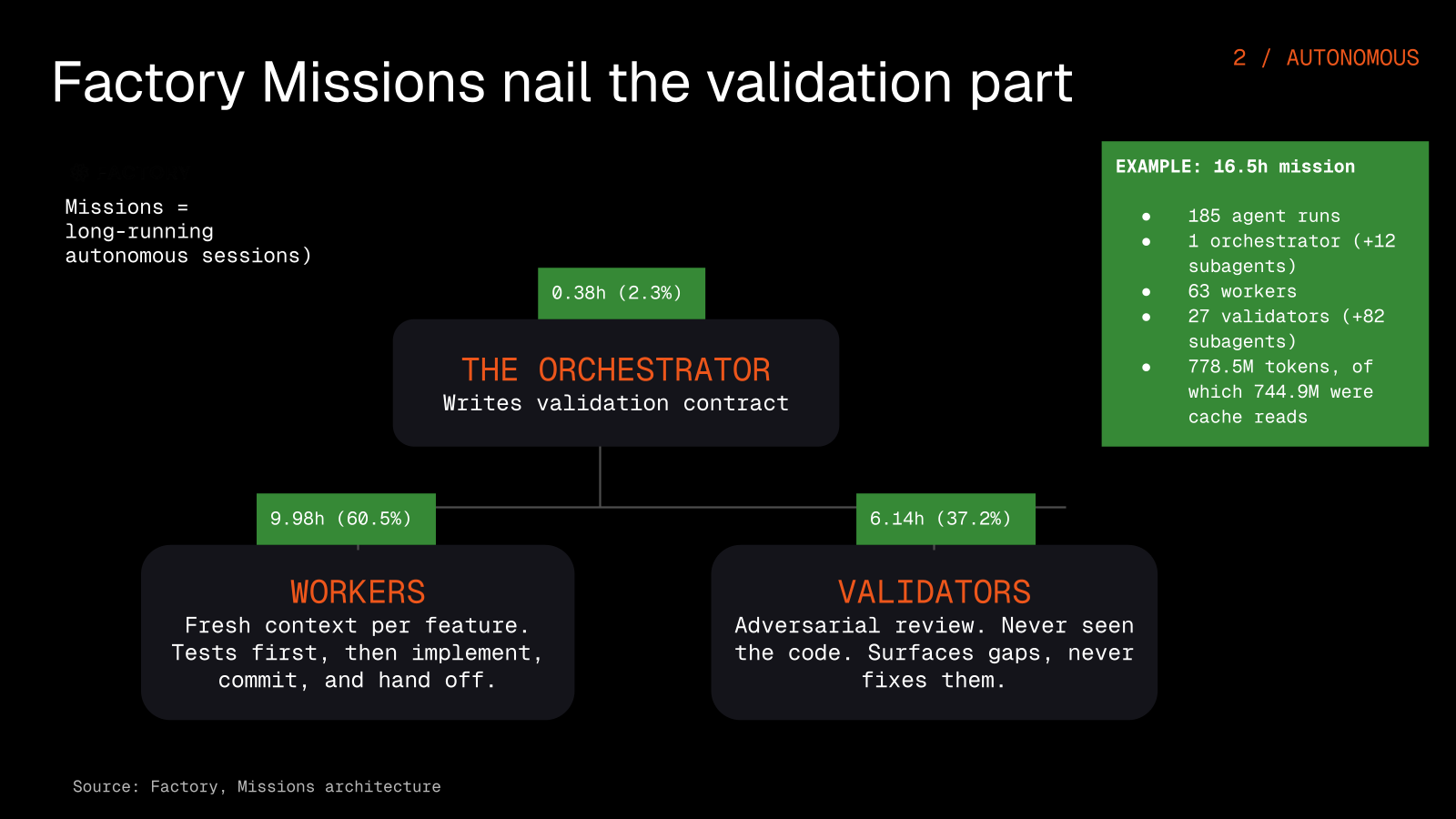
This is the three-role architecture of an orchestrator, workers, and validators, tied together by a validation contract that defines what "done" means before any code is written. The orchestrator handles the planning, the workers implement the pieces, and the validators judge the result independently.
One design choice surprised people: the workers run in sequence, not as a parallel swarm. Each one finishes its piece and hands off to the next, so the next worker starts with fresh context, the same way a colleague reviews your code with fresh eyes. A worker can still spin up its own parallel subagents for smaller jobs like web research or scaffolding files. In a real customer mission, validation alone took about 40% of the whole process, which is a good sign, not a bad one.
One real mission ran for 16.5 hours across 185 agent runs, with 63 workers and 27 validators, and used 778.5M tokens, of which 744.9M were cache reads.
If you have worked with coding agents, you have seen the pattern where the agent builds a feature, writes some tests, watches them pass, and reports the work complete, even though those tests were shaped by the same context that shaped the code. That is the reason we separate validation from generation.
The Scrutiny Validator reads the code and its trajectory, running tests, typecheck, lint, and code review, and although it can see the code it never wrote a line of it. The User-Testing Validator goes further and stays a true black box that never reads the source at all; it drives the running app through computer-use and checks the behavior against the contract.
I watched one engineer migrate a codebase this way. Other tools produced something that looked right in the code but was a dead, non-interactive dummy. Because our user-testing validator actually clicked through the running app, it caught that the result did not work, not just that it looked good. That is only possible now because computer-use and persistent virtual machines for agents finally got good.

This is Mission Control, the terminal dashboard for a long-running autonomous Mission, and what you are watching is a Droid build and maintain a project on its own, linting, testing, implementing, committing, and handing off without anyone stepping in.
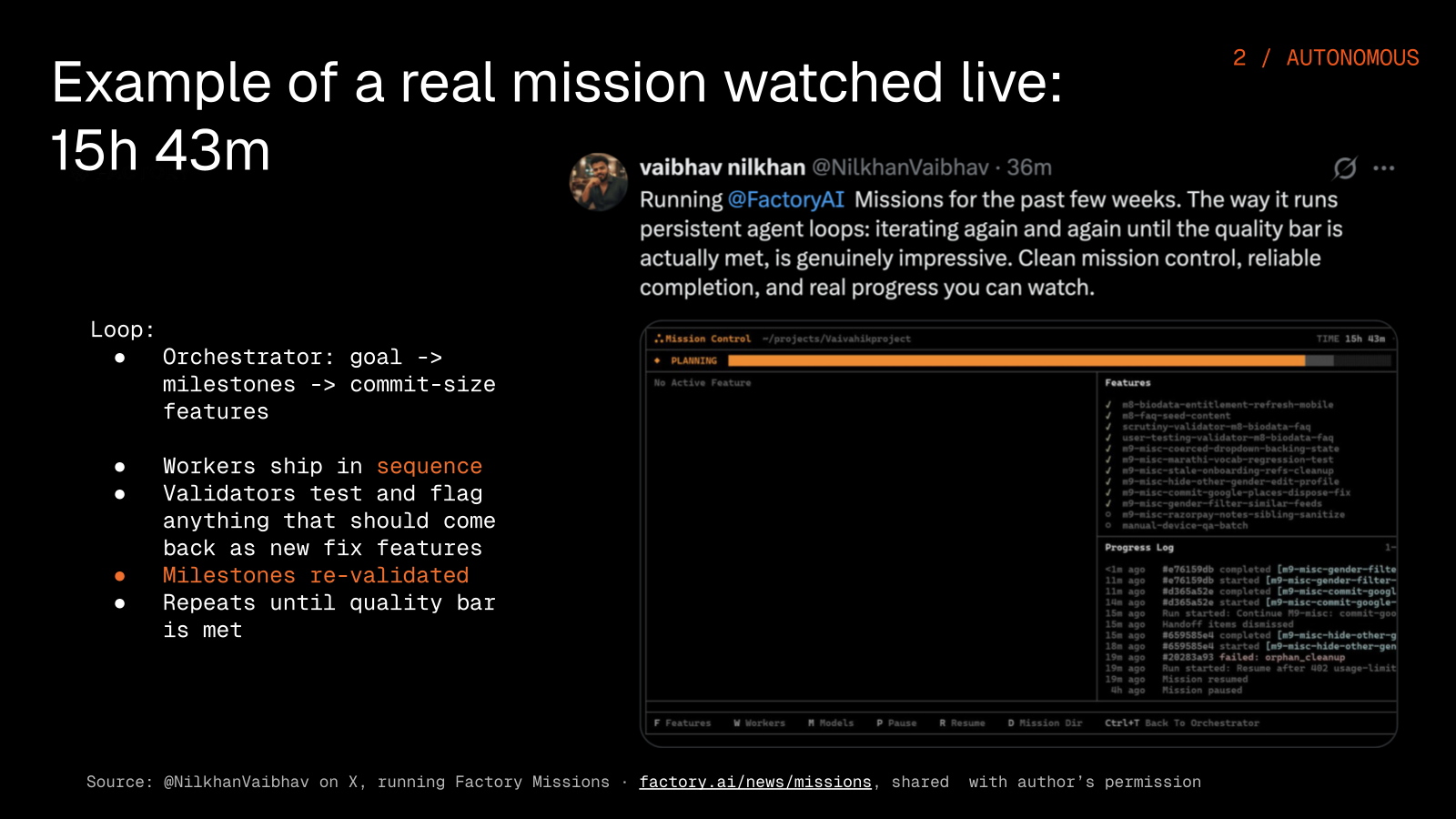
Missions run loops inside the loop. The outer loop is the mission itself, planning, implementing, validating, and iterating, while the inner loops are individual agent sessions handling subtasks, and each worker gets fresh context per feature so it does not carry stale assumptions from one task into the next.

Context is the elephant in the room, because less bloat means fewer compressions and fewer compressions mean more reliable long-horizon runs. The bottleneck for autonomous agents is reliability over long horizons rather than raw capability, and one of the biggest drivers of that reliability is how much context bloat the agent has to carry.
Enterprises are the extreme case, since they wire in hundreds of tools on average, everything from Figma and Notion to Gmail and Drive, each with its own schemas, parameters, and descriptions. Two tools that merely sound alike are enough to make an agent pick the wrong one or blow the context window and force a compression, and that is genuinely dangerous in the middle of a long mission.

The deferred context engine keeps a compact capability index and loads full schemas only on demand. It progressively discloses tools, so the agent begins with a short list and short descriptions and only fully loads a tool once the code actually needs it, and nothing is ever removed, it is just hidden and out of reach until the moment it becomes relevant. In practice this cuts input tokens by about 15% per MCP session on average, by 39% at the p90 heavy sessions, and by 51% once more than a hundred tools are deferred, and the savings keep growing with the size of the catalog.

Resources for this section:
- Factory: Introducing Missions
- Factory: How Missions Work
- Factory: Deferred Context Engine
- METR: Measuring AI Ability to Complete Long Tasks
3. Always improving
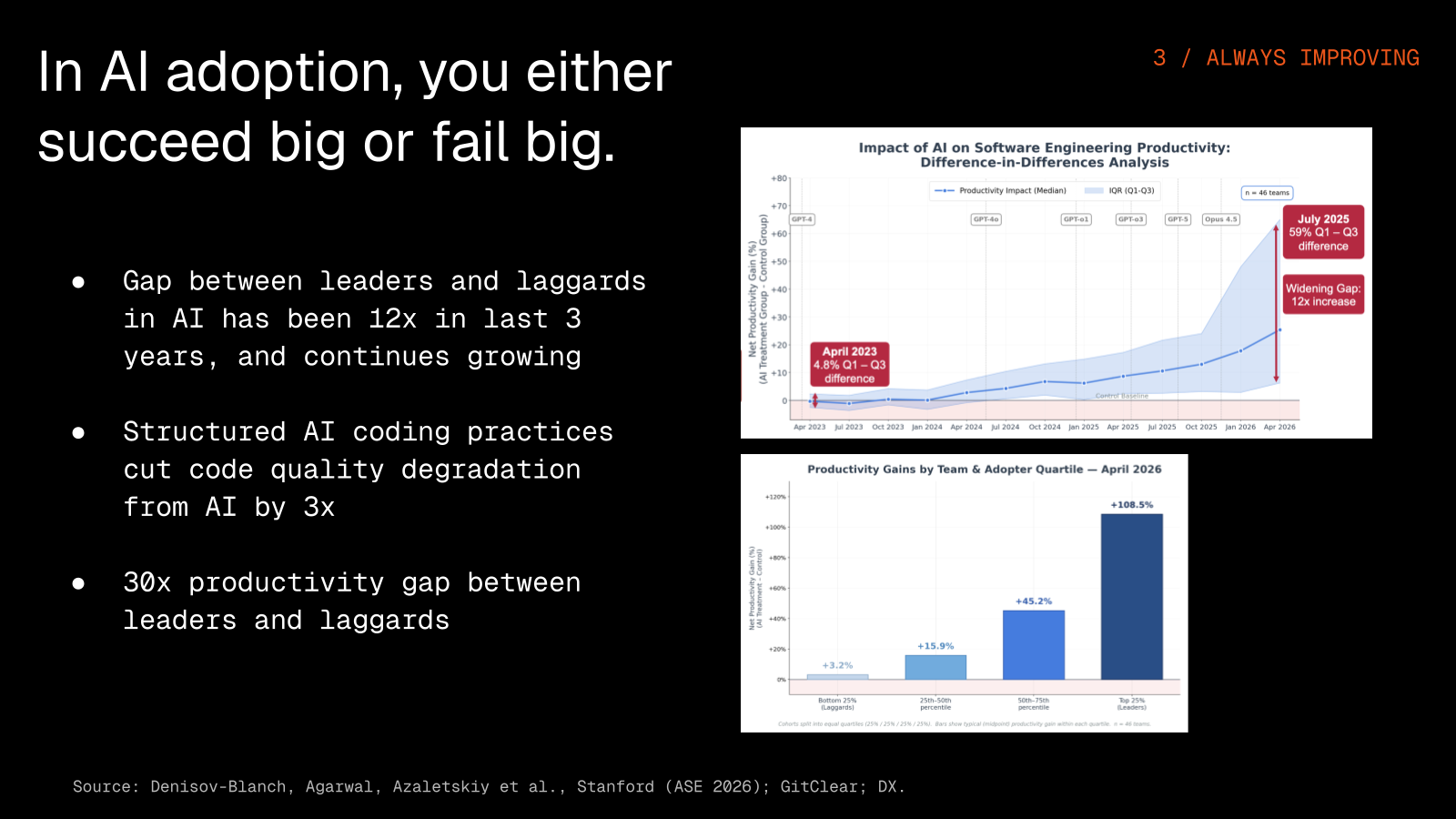
The gap between AI leaders and laggards has run about 12x over the last three years, and it follows a power law where the leaders take almost everything while the laggards lose almost everything. Agents need onboarding in the same way new engineers do, which is why good documentation and a legible codebase end up mattering as much as the code itself.
GitClear and DX both show that unstructured AI coding actually degrades code quality with more churn and more duplication, while structured practice reverses that trend, so in AI adoption you tend to either succeed big or fail big with no quiet middle left anymore.
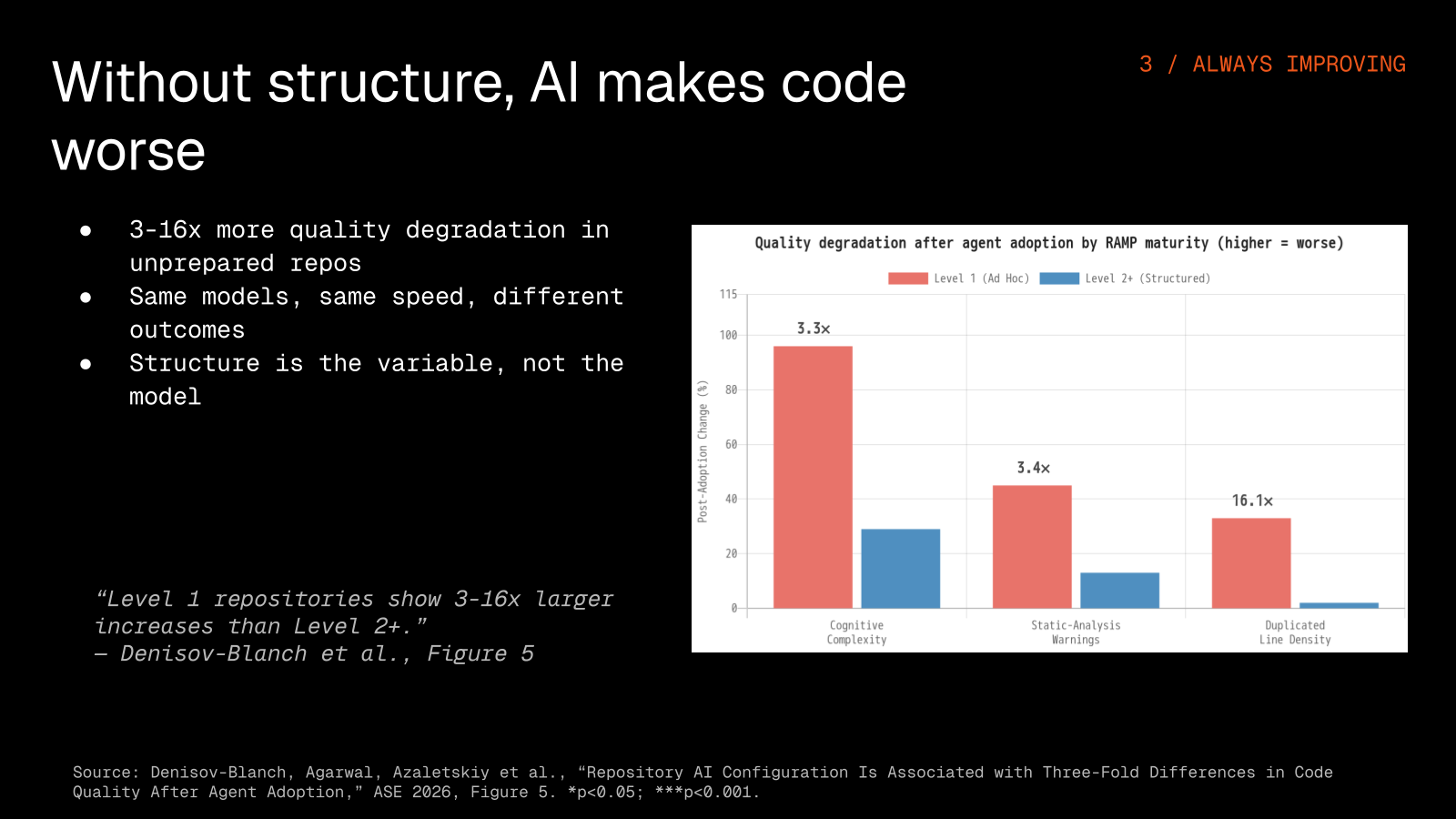
The pattern in the data is consistent: Level 1 repos with no linting config, no AGENTS.md, and no pre-commit hooks see massive quality degradation after AI adoption, while Level 2 and higher repos with even basic structure see manageable, controlled changes. It is the strongest empirical evidence we have that agent results are an environment problem rather than a model problem.
Cognitive complexity rose 96% in Level 1 repos against 29% in Level 2 and above, static-analysis warnings 45% against 13%, and duplicated line density 122% against 34%, which works out to a gap of three to four times across every metric.
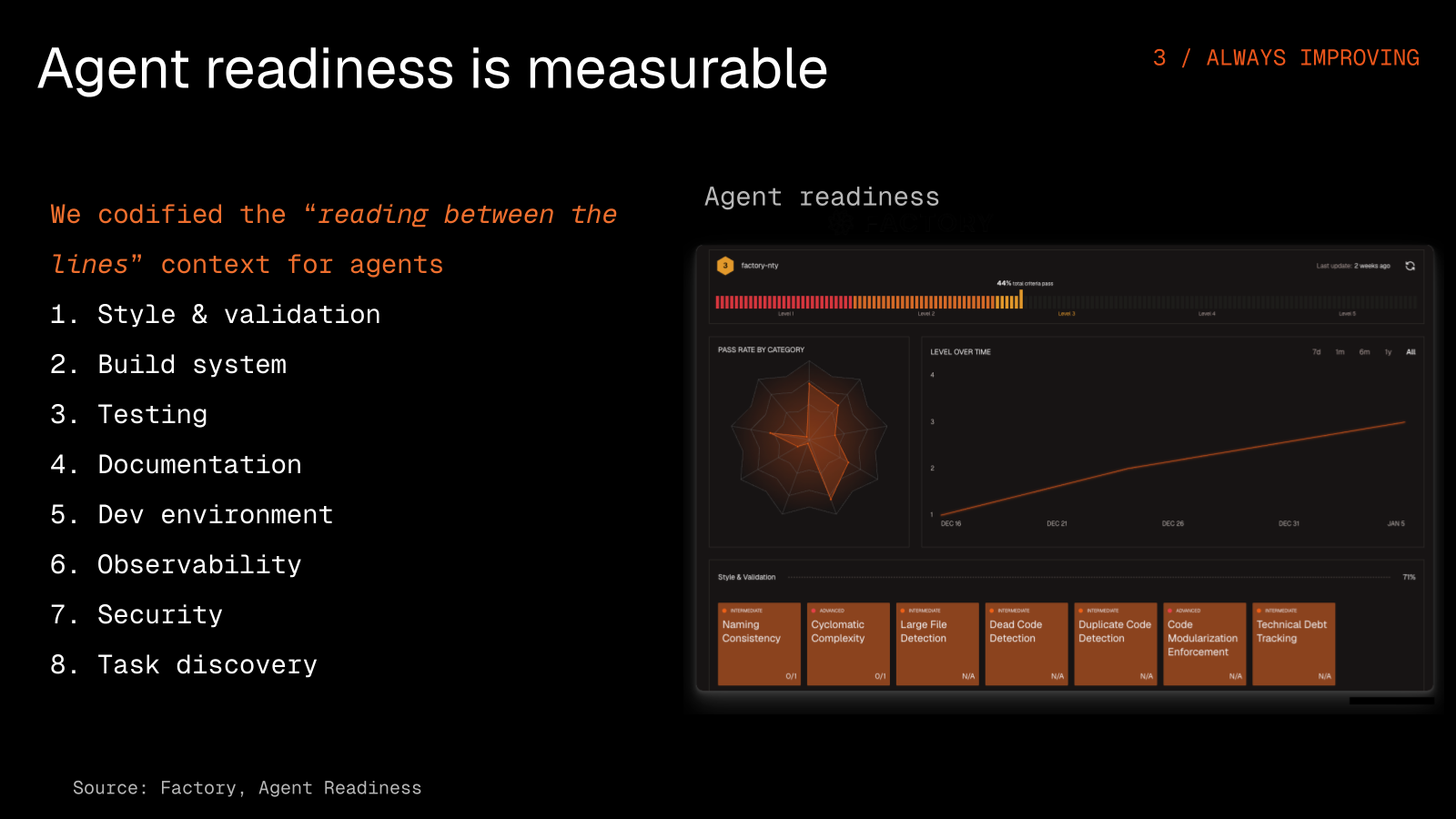
Agent-readiness is something you can measure rather than a matter of vibes. We score repositories on how well they support autonomous work across style and validation, build system, testing, documentation, dev environment, observability, security, and task discovery. None of those are vanity metrics, because they directly predict how well an agent will perform on your codebase.
Teams blame the model when the real bottleneck is missing pre-commit hooks, undocumented env vars, or build steps buried in Slack.
Most of the time working with AI, you find yourself repeating how you want things done and feeling like the agent still does not get you. It is the same problem a new hire has: every company runs on rules that are not written down anywhere, the things between the lines you only pick up by observing. Agents need a way to absorb that too.
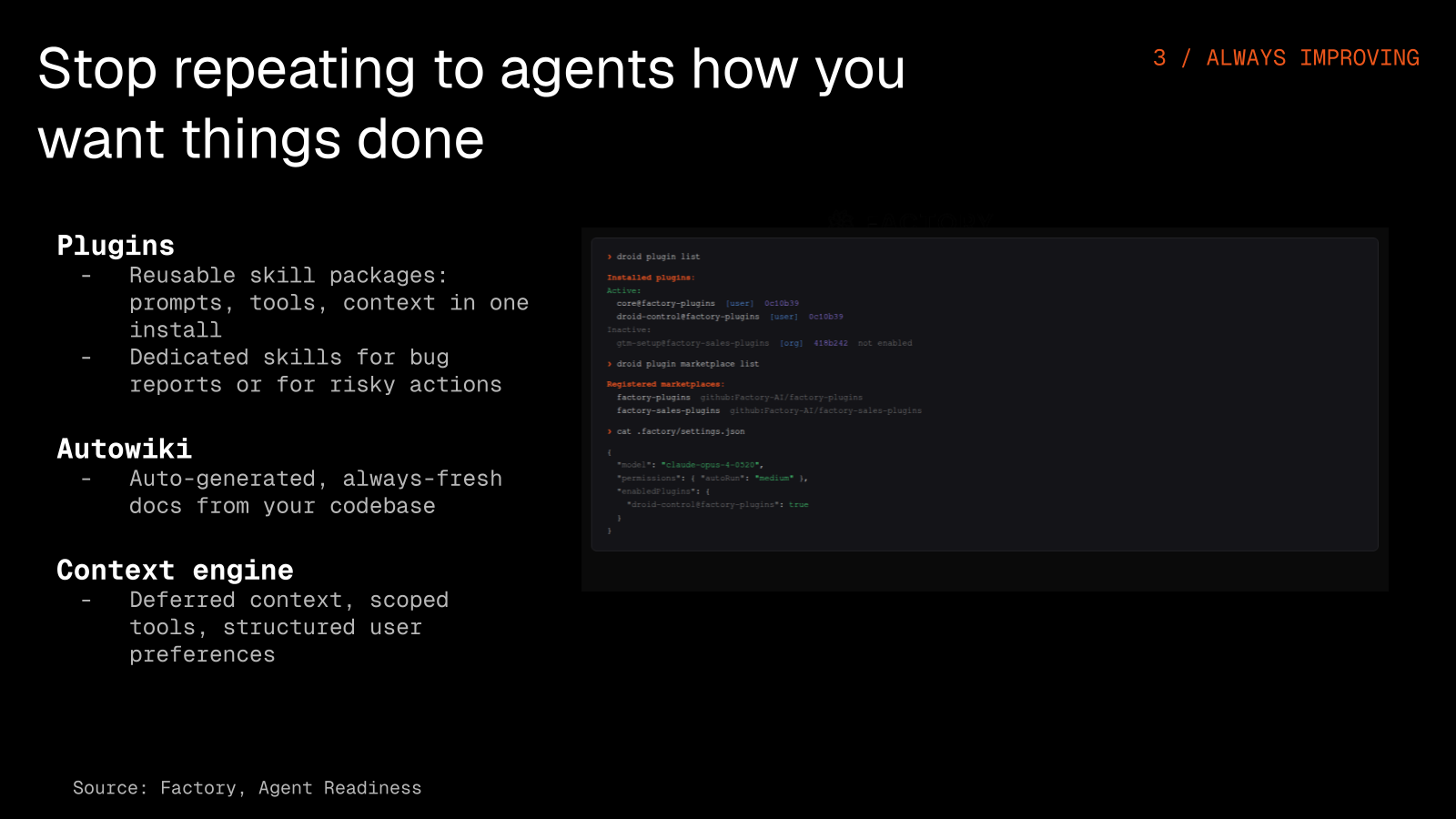
Every time you explain a preference to an agent, you are wasting tokens and time. These features encode your preferences once so the agent just knows:
- Plugins bundle skills, slash commands, hooks, and MCP server connections into one install. Think npm packages but for agent behavior.
- AutoWiki generates always-fresh documentation from your codebase automatically.
- Packaging layer ships droids, hooks, and MCP servers as versioned packages.
- Context engine uses deferred context, scoped tools, and structured user preferences.
It is the difference between hand-configuring every developer's agent vs. running droid plugin add company/standard-setup.
Resources for this section:
- Yegor Denisov-Blanch, Stanford: software engineering productivity research
- GitClear: AI code quality impact study
- DX: developer experience research
- Factory: Introducing Agent Readiness
Where we are heading
The real question, the one everyone came for, is whether the software factory replaces us.

Computer was a job title before it was a machine, and the people who held it were not written out of the story, they moved up a layer of abstraction. That is the honest way I read this shift, because the software factory does not replace engineers so much as it moves what "engineering" means up a layer.
The photo is from the 1940s, when more than 80 women were employed as human "computers" and a single ballistics trajectory by hand took 30 to 40 hours, all organized factory-style. Then compilers and high-level languages let people describe intent and stop hand-computing, and the structure of the work did not change, only the layer the humans sat at.

This is the same factory floor, except the rows of human computers are now agents, and the structure has not really changed: it is still parallel work, still factory-style organization, still a few humans directing. The only thing that moved is the layer the humans sit at.
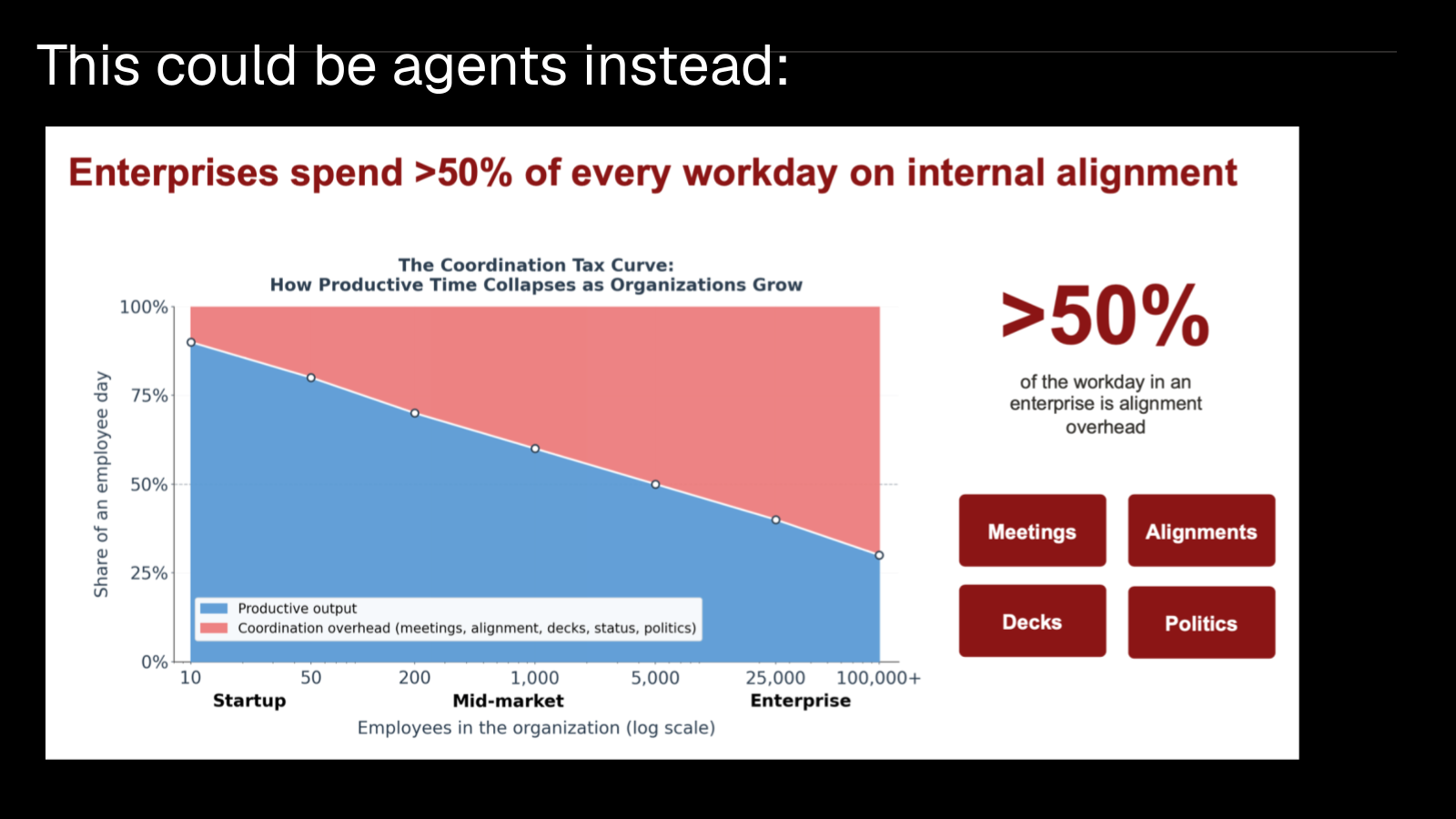
The real risk is not being replaced but refusing to move up that layer. So I want to end on the optimistic read, which is that humans should be deciding what to build rather than how to build it, because the how is exactly what the agents are for. The factory does not come for the interesting work, it comes for the annoying work, the alignment, the status updates, and the meetings that exist only to move context between people, so hand all of that to your software factory and then, as I told the room, go touch some grass and let your agents build for you.
Resources for this section: